I downloaded and hashed 4.6 million arXiv PDFs. Then the hashes changed.
It was supposed to be a weekend project. The goal was simple: build a plugin to demonstrate annotation retrieval for DorsalHub, my shiny new API.
The plugin would showcase fetching public file annotations, using only the file's SHA-256 content hash as the query. In other words, pointing at a file on your computer, and getting some structured information about that file from the API.
graph LR
A@{ shape: doc, label: "Some File" } --> B(Dorsal + Plugin)
B -- "SHA-256" --> C[(DorsalHub API)]
C -- "Annotation" --> B
My first consideration was the dataset. I was already aware of the Kaggle-hosted arXiv dataset, and this felt like a nice opportunity to play with it.
arXiv.org is a huge open-access repository for scientific papers across a number of disciplines, and the arXiv Dataset includes structured metadata about each of them. That's millions of papers dating back to the early 90s.
Looking at the dataset, it's easy to see how great a fit it is. The metadata is clean and up to date, containing almost anything a person would want to know about an arXiv paper.
I planned to use it to create annotations for millions of PDF papers. Each annotation would be a structured record of key information about the paper: Authors, Title, Abstract etc. After linking each annotation to the PDF's hash, I'd have the data to power a plugin to retrieve a structured annotation for any arXiv paper, simply by providing the content hash of the PDF.
Here's how I imagined it would look when it was finished:
dorsal run dorsalhub/arxiv-pdf ./1706.03762v7.pdf
Arxiv-id: 1706.03762
Title: Attention Is All You Need
Abstract: The dominant sequence transduction models are...
Under the hood, all the plugin had to do was to hash the file content and send that hash to the DorsalHub API. The API would then check for an arxiv annotation and, if found, would return it to the client.
This felt like something worth building.
As a demo, it's easy to explain. It showcases annotation retrieval in a way that anyone can understand. Bonus points if it's actually useful to anyone.
So I worked out a plan in two stages.
-
Backfill the PDF file hashes and arXiv annotations to DorsalHub. This becomes the queryable data.
-
Code a user-facing plugin to retrieve the arXiv annotation for any given document.
It was a Friday evening when I started, and I had the whole weekend ahead of me. I was feeling optimistic.
The Backfill
In order to retrieve an annotation from an API, first the annotation has to exist.
The steps to achieve this were straightforward:
- Download the back catalog of arXiv papers (yes, all of them)
- Parse the arXiv dataset metadata into structured annotations
- Hash and process each PDF, linking the correct annotation to its file hash
- Push it all up to the DorsalHub API
The Download
Acquiring the entire collection of arXiv PDFs isn't as difficult as it might sound. While crawling arXiv itself is out of the question (their web rate limiter is famously strict) they provide bulk access to papers in two ways:
-
Amazon S3:
s3://arxiv/pdfThis bucket holds the complete set of documents, bundled in
.tarfiles. Amazon S3 is the official bulk download method documented on arxiv.org.Note that this is a Requester Pays bucket, so downloading the PDFs this way will cost you hundreds of dollars.
-
Google Cloud Storage:
gcs:arxiv-datasetThis bucket is part of the arXiv Dataset, and is maintained alongside the metadata records. It's also free to access.
rclone lsf :gcs:arxiv-dataset/arxiv/ --gcs-anonymous --max-depth 2
arxiv-dataset/
└── arxiv/
├── pdf/ <-- Post-2007 papers are sorted by month and year
│ ├── 0704/ <-- April 2007
│ │ ├── 0704.0001v1.pdf
│ │ ├── 0704.0001v2.pdf
│ │ └── 0704.0002v1.pdf
│ ├── 0705/
│ └── ...
├── math/ <-- Pre-2007 papers are organized by subject e.g. math
│ ├── pdf/
│ │ ├── 9201/ <-- January 1992
│ │ │ └── 9201201v1.pdf
│ │ └── ...
│ └── ...
├── cs/
│ ├── pdf/
│ └── ...
└── (more subject categories...)
A note on arXiv IDs
Every arXiv submission is assigned a unique ID, e.g.
0704.0001orcs/9301101.
Pre-2007: The ID combines the subject with its submission date and sequence number. For example,
cs/9301101was submitted to the Computer Science (cs) category in January 1993 (9301) as number101for CS for that month.2007 and newer: The ID is globally unique, dropping the subject. For example,
0704.0001is simply the first (0001) paper submitted to arXiv in April 2007 (0704).Versions: arXiv IDs optionally include a version number suffix (
v1,v2). When papers are re-submitted, arXiv publishes a corrected paper with an incremented version number (0704.0001v2). IDs with the version omitted (0704.0001) implicitly refer to the latest existing version.For more information on arXiv identifiers, see: http://info.arxiv.org/help/arxiv_identifier.html
After making sure I had a few terabytes spare on my local NAS, I opened a terminal window, logged into it and used Rclone to begin the process of mirroring the Google Cloud Storage (GCS) bucket. Even with my reasonably fast connection, this was going to take a while.
The biggest pain point is that the GCS bucket holds the PDFs as loose files in a deeply nested structure. This means that each tiny PDF has to be downloaded and written to disk individually. Even using Rclone with multiple workers, the overhead from writing so many tiny files to the multi-disk array meant progress was slow. I tried increasing the worker count to up the pace, but this slowed down progress even more, as the disks couldn't keep up and began thrashing.
After a few false starts, I managed to find a balance which kept the NAS volume utilization (a metric for how much work the disks are doing) at around 80 to 90%. This prevented disk thrashing and kept the download rate steady.
Here's the command I used to mirror the large post-2007 arxiv-dataset/arxiv/pdf/ path, which contains the vast majority of the PDFs. I chose to run Rclone via Docker to keep the process isolated and easier to manage for what I anticipated would be a long task:
docker run -d \
--name mirror \
--restart always \
-v /volume1/arXiv/arxiv_mirror/pdf:/data \
rclone/rclone:latest \
copy :gcs:arxiv-dataset/arxiv/pdf/ /data/ \
--gcs-anonymous \
--transfers 25 \
--checkers 25 \
--progress \
--create-empty-src-dirs \
--include "*.pdf"
With the NAS making reassuringly busy noises, all I had to do was wait.
The Metadata
On Saturday morning, I checked the download progress. About 10 to 15 PDFs were landing on my NAS every second, but most of the file tree was still empty. A little under 1 TB had downloaded so far, but I didn't have a great idea of how much remained.
Unlike a hard drive on your computer, where an index table helps do things like quickly count how many files are in a directory, GCS buckets are object storage. This means that there aren't really any directories per se.
Checking how many files were left to download would involve iterating over every object in the bucket, filtering for the files I care about, and summing up their reported size attributes. For a bucket containing millions and millions of files, this would take hours.
Seriously, don't bother executing this command:
gsutil du -sh "gs://arxiv-dataset/arxiv/**/*.pdf"
Since I didn't have the patience for counting the PDFs in the GCS bucket, I tried my best to estimate based on reported historic stats about the AWS bucket:
- The total size of the bucket was 5.6 TB in 2023, growing to 9.2 TB in April 2025
- Roughly half of the total is PDF files, the rest being occasional HTML submissions, LaTeX and other source files
I was doing this backfill in February 2026. Factoring in accelerating monthly submission growth, I estimated that when it was complete I'd have between 5 TB and 6 TB of PDF files to process.
This was not going to be a weekend project.
While Rclone continued in the background, I had some time on my hands and began digging into the arXiv Dataset.
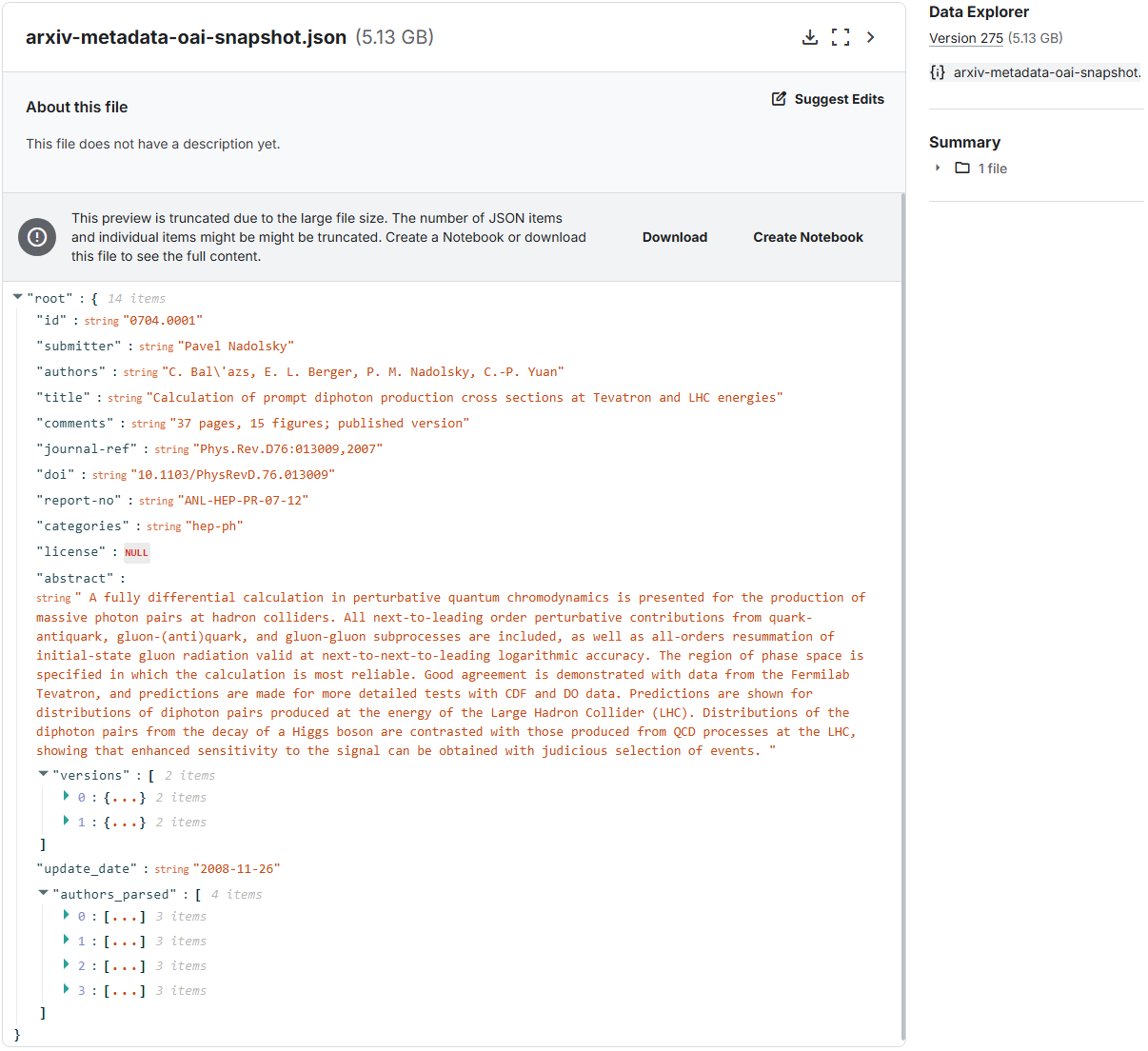
Each record in the dataset is already a well defined JSON object, and contains a great deal of information about the submission. Here's an example:
{
"id": "1706.03762",
"submitter": "Llion Jones",
"authors": "Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion\n Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin",
"title": "Attention Is All You Need",
"comments": "15 pages, 5 figures",
"journal-ref": null,
"doi": null,
"report-no": null,
"categories": "cs.CL cs.LG",
"license": "http://arxiv.org/licenses/nonexclusive-distrib/1.0/",
"abstract": " The dominant sequence transduction models are based on complex recurrent or\nconvolutional neural networks in an encoder-decoder configuration. The best\nperforming models also connect the encoder and decoder through an attention\nmechanism. We propose a new simple network architecture, the Transformer, based\nsolely on attention mechanisms, dispensing with recurrence and convolutions\nentirely. Experiments on two machine translation tasks show these models to be\nsuperior in quality while being more parallelizable and requiring significantly\nless time to train. Our model achieves 28.4 BLEU on the WMT 2014\nEnglish-to-German translation task, improving over the existing best results,\nincluding ensembles by over 2 BLEU. On the WMT 2014 English-to-French\ntranslation task, our model establishes a new single-model state-of-the-art\nBLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction\nof the training costs of the best models from the literature. We show that the\nTransformer generalizes well to other tasks by applying it successfully to\nEnglish constituency parsing both with large and limited training data.\n",
"versions": [
{"version": "v1", "created": "Mon, 12 Jun 2017 17:57:34 GMT"},
{"version": "v2","created": "Mon, 19 Jun 2017 16:49:45 GMT"},
{"version": "v3","created": "Tue, 20 Jun 2017 05:20:02 GMT"},
{"version": "v4","created": "Fri, 30 Jun 2017 17:29:30 GMT"},
{"version": "v5","created": "Wed, 6 Dec 2017 03:30:32 GMT"},
{"version": "v6","created": "Mon, 24 Jul 2023 00:48:54 GMT"},
{"version": "v7","created": "Wed, 2 Aug 2023 00:41:18 GMT"}
],
"update_date": "2023-08-03",
"authors_parsed": [
["Vaswani", "Ashish", ""],
["Shazeer", "Noam", ""],
["Parmar", "Niki", ""],
["Uszkoreit", "Jakob", ""],
["Jones", "Llion", ""],
["Gomez", "Aidan N.",""],
["Kaiser", "Lukasz", ""],
["Polosukhin", "Illia", ""]
]
}
This is a very clean JSON, from a well maintained dataset with great coverage. There wasn't much work to do, apart from choosing which fields to keep.
All annotations on DorsalHub must conform to a known schema. I already had it in the back of my mind that I would bundle an adapter with the plugin, allowing automatic export to standard citation formats (e.g. BibTeX or CSL-JSON). This meant the schema I built would have to capture at least those fields needed to build a citation.
In the end I constructed the dorsal/arxiv schema. This JSON schema defines the shape of a single annotation, and when applied to the same record above, results in the following:
{
"arxiv_id": "1706.03762",
"title": "Attention Is All You Need",
"abstract": "The dominant sequence transduction models are based on complex recurrent or\nconvolutional neural networks in an encoder-decoder configuration. The best\nperforming models also connect the encoder and decoder through an attention\nmechanism. We propose a new simple network architecture, the Transformer, based\nsolely on attention mechanisms, dispensing with recurrence and convolutions\nentirely. Experiments on two machine translation tasks show these models to be\nsuperior in quality while being more parallelizable and requiring significantly\nless time to train. Our model achieves 28.4 BLEU on the WMT 2014\nEnglish-to-German translation task, improving over the existing best results,\nincluding ensembles by over 2 BLEU. On the WMT 2014 English-to-French\ntranslation task, our model establishes a new single-model state-of-the-art\nBLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction\nof the training costs of the best models from the literature. We show that the\nTransformer generalizes well to other tasks by applying it successfully to\nEnglish constituency parsing both with large and limited training data.",
"authors": [
"Ashish Vaswani",
"Noam Shazeer",
"Niki Parmar",
"Jakob Uszkoreit",
"Llion Jones",
"Aidan N. Gomez",
"Lukasz Kaiser",
"Illia Polosukhin"
],
"categories": [
"cs.CL",
"cs.LG"
],
"doi": null,
"journal_ref": null,
"license": "http://arxiv.org/licenses/nonexclusive-distrib/1.0/",
"version": "v7",
"url": "https://arxiv.org/abs/1706.03762"
}
This new validated record retains all of the information needed to build a citation.
For example, a user could ask the Dorsal CLI for a BibTeX reference by passing an --export argument:
dorsal run dorsalhub/arxiv-pdf ./1706.03762v7.pdf --export=bibtex
@misc{1706_03762,
title = {Attention Is All You Need},
author = {Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and
Illia Polosukhin},
eprint = {1706.03762},
archivePrefix = {arXiv},
primaryClass = {cs.CL},
url = {https://arxiv.org/abs/1706.03762},
year = {2017},
month = {6}
}
The Test
By this point I'd resigned myself to the fact that the download would take days to finish. Until it was complete, I couldn't fully move on to the next stage: actually processing the documents. But what I could do was test the workflow end to end, and validate my assumptions.
So I trusted Rclone to do its job, and in the meantime I copied over a few months worth of PDFs and started to test things out.
Processing a PDF means extracting core metadata. This forms a structured record that can be synced with DorsalHub, which contains fields like size, media_type, and pdf.page_count.
I processed a few hundred files, linking each to the schema-validated annotations parsed out of the arXiv dataset, and pushed them to my testing (dev) instance of the DorsalHub API.
Now I had queryable data for a sample of documents. This meant I could:
- Point at a file
- Calculate its SHA-256 hash
- Query the API with that hash
- Get an annotation back
I could test this in two steps, using the Dorsal CLI.
- First, use
dorsal idto get the file record from the API:
dorsal id /mnt/b/arxiv_mirror/pdf/1706/1706.03762v7.pdf
🔎 Identifying file 1706.03762v7.pdf...
╭──────────────────────────────── File Identified ──────────────────────────────────╮
│ │
│ Hashes │
│ SHA-256: b7d72988fd8107d07f7d278bf0ba6621adb6ed47df74be4014fa4a01f03aff6a │
│ │
│ File Info │
│ Name: 1706.03762v7.pdf │
│ Size: 2 MiB │
│ Media Type: application/pdf │
│ │
│ Tags │
│ No tags found. │
│ │
│ Pdf Info → file/pdf │
│ producer: pdfTeX-1.40.25 │
│ version: 1.5 │
│ page_count: 15 │
│ creation_date: 2023-08-03T00:07:29Z │
│ modified_date: 2023-08-03T00:07:29Z │
│ │
│ Arxiv Info → dorsal/arxiv │
│ Source: Model (arXiv Dataset) │
│ Modified: 2026-02-14 10:00 │
│ ID: 77fc8be9-c53e-4461-b5c2-e015d8682aea │
│ │
│ │
╰────────────────────────────────────────────────────────────────────────────────────╯
- Then, with the
dorsal/arxivannotation ID copied from the record above, rundorsal annotation get:
dorsal annotation get 77fc8be9-c53e-4461-b5c2-e015d8682aea
╭───────────────────────────────── ArXiv Record Result ─────────────────────────────────╮
│ dorsal/arxiv ID: 77fc8be9-c53e-4461-b5c2-e015d8682aea │
│ ───────────────────────────────────────────────────────────────────────────────────── │
│ │
│ Attention Is All You Need │
│ 1706.03762 (v7) │
│ Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. │
│ Gomez, Lukasz Kaiser, Illia Polosukhin │
│ │
│ ╭──────────────────────────────────── Abstract ─────────────────────────────────────╮ │
│ │ The dominant sequence transduction models are based on complex recurrent or │ │
│ │ convolutional neural networks in an encoder-decoder configuration. The best │ │
│ │ performing models also connect the encoder and decoder through an attention │ │
│ │ mechanism. We propose a new simple network architecture, the Transformer, based │ │
│ │ solely on attention mechanisms, dispensing with recurrence and convolutions │ │
│ │ entirely. Experiments on two machine translation tasks show these models to be │ │
│ │ superior in quality while being more parallelizable and requiring significantly │ │
│ │ less time to train. Our model achieves 28.4 BLEU on the WMT 2014 │ │
│ │ English-to-German translation task, improving over the existing best results, │ │
│ │ including ensembles by over 2 BLEU. On the WMT 2014 English-to-French │ │
│ │ translation task, our model establishes a new single-model state-of-the-art │ │
│ │ BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction │ │
│ │ of the training costs of the best models from the literature. We show that the │ │
│ │ Transformer generalizes well to other tasks by applying it successfully to │ │
│ │ English constituency parsing both with large and limited training data. │ │
│ ╰───────────────────────────────────────────────────────────────────────────────────╯ │
│ │
│ URL https://arxiv.org/abs/1706.03762 │
│ Categories cs.CL, cs.LG │
│ License http://arxiv.org/licenses/nonexclusive-distrib/1.0/ │
╰───────────────────────────────────────────────────────────────────────────────────────╯
All the plugin had to do was streamline that two-step process into a single step.
Everything was working exactly as it should.
Right up until the moment it wasn't.
You see, people don't typically download these papers from the Google Cloud Storage bucket. Most people (myself included) go to the arxiv.org page, click "View PDF", and either read it in their web browser or save it to their computer to read later.
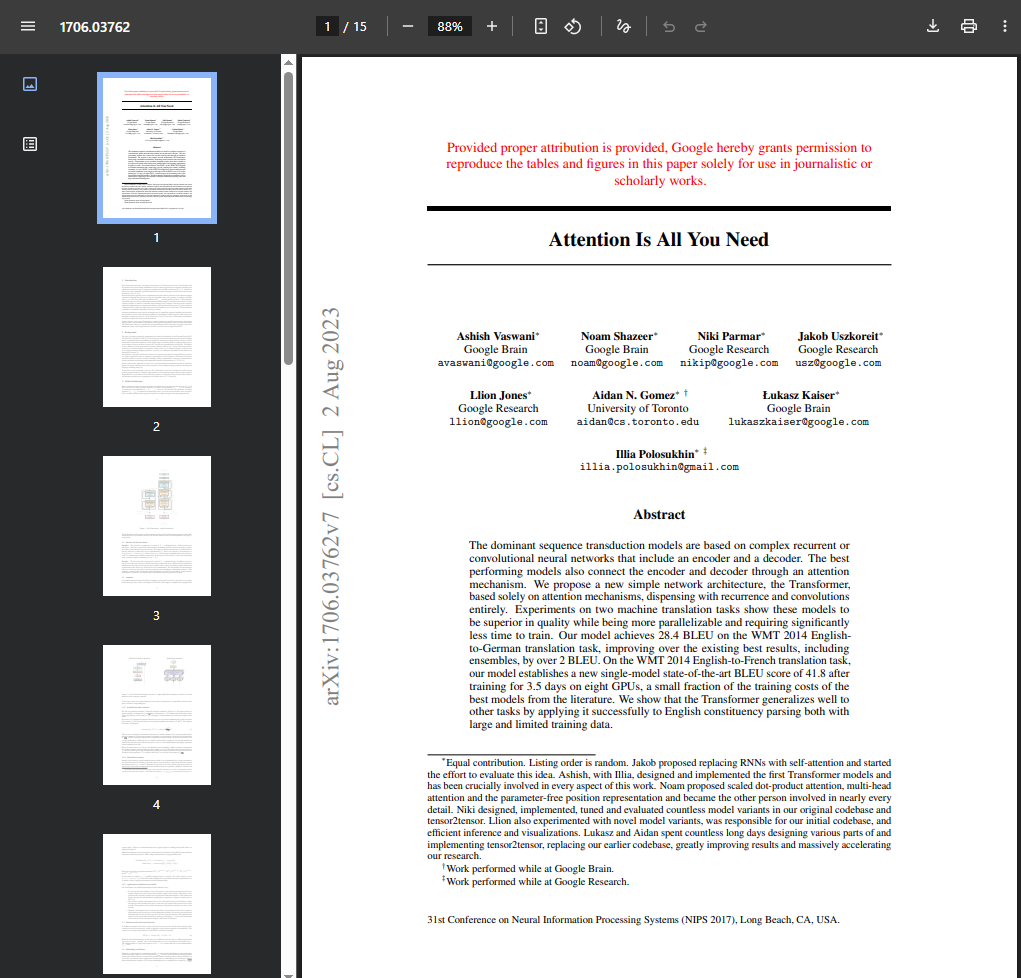
The first time I tested the workflow using a newly downloaded PDF, I noticed something strange: it wasn't working.
The hash was different.
shasum -a 256 /mnt/b/arxiv_mirror/pdf/1706/1706.03762v7.pdf | awk '{print $1}'
b7d72988fd8107d07f7d278bf0ba6621adb6ed47df74be4014fa4a01f03aff6a
shasum -a 256 /mnt/c/Users/Rio/Downloads/1706.03762v7.pdf | awk '{print $1}'
bdfaa68d8984f0dc02beaca527b76f207d99b666d31d1da728ee0728182df697
Same paper. Same version. Different hash.
So I downloaded it again, and checked again. Maybe it was corrupted, even a single byte of difference is enough for an entirely different SHA-256 hash. But the outcome was identical: same paper, same version, same filesize, but a different hash.
So I selected a different paper. I downloaded it from arxiv.org and checked my dev API for its hash. This time it worked flawlessly. The API returned the annotation because the file hash was the same. The file hash was the same because the file was byte-identical.
I did this a few more times and the results were mixed: Sometimes the file content was identical to the copy on arxiv.org, but more often than not, the SHA-256 hashes did not match.
The Comparison
A Note on File Hashes
A file hash is a long sequence of letters and numbers (usually a hexadecimal representation) which can be used to identify a file.
The most important feature of a cryptographic file hash (like SHA-256) is its uniqueness: if any two files are different by even a single byte, the secure cryptographic file hash of each of those files will be different.
This file was downloaded from the GCS bucket:
dorsal file scan /mnt/b/arxiv_mirror/pdf/1706/1706.03762v7.pdf
📄 Scanning metadata for 1706.03762v7.pdf
╭────────────────────────── File Record: 1706.03762v7.pdf ───────────────────────────╮
│ │
│ Hashes │
│ SHA-256: b7d72988fd8107d07f7d278bf0ba6621adb6ed47df74be4014fa4a01f03aff6a │
│ │
│ File Info │
│ Full Path: /mnt/b/arxiv_mirror/pdf/1706/1706.03762v7.pdf │
│ Modified: 2023-08-03 01:07:33 │
│ Name: 1706.03762v7.pdf │
│ Size: 2 MiB │
│ Media Type: application/pdf │
│ │
│ Tags │
│ No tags found. │
│ │
│ Pdf Info → file/pdf │
│ creator: LaTeX with hyperref │
│ producer: pdfTeX-1.40.25 │
│ version: 1.5 │
│ page_count: 15 │
│ creation_date: 2023-08-03T00:07:29Z │
│ modified_date: 2023-08-03T00:07:29Z │
│ │
│ │
╰────────────────────────────────────────────────────────────────────────────────────╯
This file was downloaded from arxiv.org:
dorsal file scan /mnt/c/Users/Rio/Downloads/1706.03762v7.pdf
📄 Scanning metadata for 1706.03762v7.pdf
╭────────────────────────── File Record: 1706.03762v7.pdf ───────────────────────────╮
│ │
│ Hashes │
│ SHA-256: bdfaa68d8984f0dc02beaca527b76f207d99b666d31d1da728ee0728182df697 │
│ │
│ File Info │
│ Full Path: /mnt/c/Users/Rio/Downloads/1706.03762v7.pdf │
│ Modified: 2026-02-07 13:43:07 │
│ Name: 1706.03762v7.pdf │
│ Size: 2 MiB │
│ Media Type: application/pdf │
│ │
│ Tags │
│ No tags found. │
│ │
│ Pdf Info → file/pdf │
│ creator: LaTeX with hyperref │
│ producer: pdfTeX-1.40.25 │
│ version: 1.5 │
│ page_count: 15 │
│ creation_date: 2024-04-10T21:11:43Z │
│ modified_date: 2024-04-10T21:11:43Z │
│ │
│ │
╰────────────────────────────────────────────────────────────────────────────────────╯
- Both files are v7 of the paper Attention is All you Need (v1 was submitted in June 2017, while v7 was submitted in August 2023).
- Both files are exactly 2,215,244 bytes (approx 2 MiB)
- Both files were compiled with version
1.40.25of pdfTeX
But there is one crucial difference: the one downloaded from GCS was compiled in August 2023; while the one downloaded from the web was compiled more recently in April 2024. We can see this from the creation_date field in the outputs above (note: creation_date is simply how Dorsal labels the PDF core metadata field /CreationDate)
In fact, when we compare the byte-content of the two files side-by-side, they are 99.9935% identical.
Running cmp, we can see just 145 of the file's 2,215,244 bytes are different:
cmp -l \
/mnt/b/arxiv_mirror/pdf/1706/1706.03762v7.pdf \
/mnt/c/Users/Rio/Downloads/1706.03762v7.pdf | wc -l
145
Those 145 bytes of difference are more than enough to ensure each file has a unique SHA-256 hash.
Let's diff the text content in each PDF:
diff --color -u \
<(strings /mnt/b/arxiv_mirror/pdf/1706/1706.03762v7.pdf) \
<(strings /mnt/c/Users/Rio/Downloads/1706.03762v7.pdf)
Running this confirms that just three values differ between the documents:
Downloaded from the GCS bucket in February 2026:
CreationDate: 2023-08-03T00:07:29Z
ModDate: 2023-08-03T00:07:29Z
ID: <45ed92c40015149e90332d9c2e25aa60>
Downloaded from arxiv.org in February 2026:
CreationDate: 2024-04-10T21:11:43Z
ModDate: 2024-04-10T21:11:43Z
ID: <ff3e15dfc6c8c63548b1c64bc2982fdb>
I repeated this comparison multiple times: I downloaded a PDF from arxiv.org and compared it to its GCS mirror doppelganger.
The results were all over the place:
- Sometimes the hashes matched, sometimes they didn't
- Sometimes the file size was the same, sometimes it wasn't
- Occasionally (like in the
1706.03762v7.pdfexample) the only difference was the compilation date
A Note on arXiv Submissions
When someone submits a paper to arXiv, they don't typically upload a PDF directly. The vast majority of papers are submitted as a "raw" bundle of LaTeX files, figures and images which, when compiled by a toolkit such as pdfTeX or GhostScript, form a publication-quality PDF.
From the sample I took, in all cases where the hash was not identical, the two PDFs were compiled at different times, often with different versions of Ghostscript or pdfTeX. This was more than enough to ensure those document pairs had different SHA-256 hashes.
This was an interesting, but deeply frustrating finding. It completely broke my mental model of the arXiv frontend as a static cache of PDF papers, as arXiv was seemingly willing to switch to serving a newer variant of a particular version of a paper.
In short: there was no guarantee that the PDF in the GCS bucket was the same PDF that you would download from the website.
I wanted to use the GCS PDFs to backfill data for a hash-powered inference plugin, but if a single version of a PDF paper could have more than one variant, each with a different hash, what hope was there?
At this point, I started to think about walking away. Maybe I could find a nice, stable set of files to work with. But I couldn't bring myself to. I was in too deep. I actually wanted to know more about what was going on with these papers:
- What proportion of the GCS PDFs have different hashes from the web PDFs?
- Are there any patterns in when the PDFs were built?
- How close could I get to a working plugin using the GCS data?
To answer those questions, I needed to complete the backfill.
Processing those documents and running my own analysis of the file hashes was the only way to get a full picture of what's going on. I logged off for the day. I wanted to focus on something else, anything else, while the NAS rumbled along in the background.
The Mirror
The NAS finally went quiet on Wednesday afternoon. Rclone had successfully finished building the arXiv mirror: 4,653,819 PDFs had landed since it started on Friday evening. 8.31 TB in total.

I now had everything I needed to start the next phase: processing the documents at scale.
The Process
Looking back, I was surprisingly unfazed at the prospect of processing 4.6 million documents. The biggest bottleneck, to be clear, is hashing. To securely hash a file, you have to read every single byte into memory. This makes file processing an I/O bound operation, which means that you can only process files as quickly as you can read them into the computer's memory.
I decided to tackle it one directory at a time. I would batch documents as they appeared in my file tree, starting with categories (acc-phys, adap-org, ...) and ending with the PDFs organized by date (from 0704 to 2602).
In a Jupyter notebook, I loaded the complete set of arXiv annotations into a dictionary in memory, and began processing the files with Dorsal. I serialized Dorsal's Pydantic outputs to disk for inspection later, and pushed the annotation-linked metadata to the API in batches.
As the script ran I observed the processing rate. It was getting through maybe 8 to 10 documents per second on average. This may sound respectable, but for a weekend project now well into its sixth day, this meant I was looking at another week at least of my computer just extracting the PDFs.
I had to speed things along.
The obvious answer was to use multi-threading. Multi-threading is an approach where processing is split across the numerous execution channels which are baked into modern CPUs. I was currently using just one of my CPU's 12 logical cores, so threading would make it possible for the other cores to help out, and increase my extraction rate.
There was just one problem: the PDF extraction logic in Dorsal has a hard dependency on pdfium, and pdfium is not thread safe. Using non-thread safe code in a threaded environment is the ultimate "at your own risk" strategy.
A Note on Thread Safety
When you run a multi-threaded program, each of those separate threads share the same memory space.
Thread safety is a guarantee given to a codebase that, when it is run in a multi-threaded environment, there will be no unintended interactions. This means using things like memory locks (mutexes) to make sure only one thread can modify a data structure at a given time.
If code is not thread safe, it makes no such guarantees. Certain objects or classes in memory may not be safe to access by more than one thread, and may lead to all kinds of problems including memory corruption, crashes or data loss.
Naturally, I decided to try my luck. Dorsal's use of pdfium is limited to reading a few pieces of core metadata from the document. So I crafted my wings and attached them with wax: I imported python's ThreadPoolExecutor and set my max_workers to 6. I submitted extraction tasks to each worker. And it worked flawlessly. At least at first.
With six threads, I was chewing through maybe 40 documents per second. A week of processing had turned into a task that could finish by tomorrow. Then I checked the annotations as they landed on the API. There was a problem.
The metadata record for each file I was processing is composed of three separate "annotations":
file/base: a generic file annotation. It has attributessize,name,media_typeand so on.file/pdf: which contains core PDF information:title,producer,page_count, etc.dorsal/arxiv: which contains the arXiv metadata:authors,abstract,url, etc.
In most of the records I checked, the file/pdf annotation was entirely missing. In the payload that landed on the server it was null. I checked the debug logs, and they confirmed the problem: an uncaught "File access error" for the majority of documents.
Threading wasn't going to work.
When multi-threading isn't an option, it's often worth looking into multi-processing. Unlike threads, which share memory, Python's ProcessPoolExecutor spins up completely isolated processes. Each process gets its own Python interpreter and separately imports dorsal and pdfium. No shared memory means no thread safety concerns.
But there was a catch. Because the processes are isolated, the huge dictionary of arXiv annotations I had loaded into memory had to be shared somehow. With pooled processes, Python has to constantly "pickle" and "unpickle" (serializing and deserializing the data) back and forth when processes access shared data. Because each process was assigned a task which it completed in a fraction of a second, the CPU was spending more time packaging and unpackaging keys and values, than actually doing the work of processing. That overhead was enough to cancel out all benefits of using multi-processing, and I was barely able to peak at 12 documents per second.
The alternative wasn't much better. I could bypass the executor pool entirely and just run multiple scripts in different terminals or notebooks. This way I overcame the pickling slowdown problem, but there was a hole in that plan too: the dictionary of arXiv annotations was over 4 GB. My desktop machine only has 64 GB of RAM. That might sound like plenty, but once you spin up multiple python processes, each with the weight of a 4GB+ dictionary, you will quickly run out.
graph LR
subgraph "Hitting RAM limits"
NAS1[(NAS Drive)]
subgraph W1["Process 2"]
D1[(4 GB arXiv<br>Annotations)]
end
subgraph W2["Process 3"]
D2[(4 GB arXiv<br>Annotations)]
end
subgraph W3["Process ..."]
D3[(4 GB arXiv<br>Annotations)]
end
subgraph W4["Process 1"]
D4[(4 GB arXiv<br>Annotations)]
end
NAS1 --PDFs--> W1 & W2 & W3 & W4
end
I needed something better.
The Hack
I went back to my serial processing script. I modified it to process just one directory of files, and wrote a separate "launcher" which I could run from the command line. The launcher would open a new console window for each directory of files: the console would iterate over each PDF, serialize the result and push to DorsalHub in batches.
I estimated I'd want to process eight to ten directories at once. I didn't have the RAM for that if I had to load a 4GB+ dictionary into each process. But what about if they could share?
Redis is an in-memory key-value store database which I use in production every day. For a python process, accessing a key from a shared Redis instance isn't much harder than grabbing a value from a local dictionary, and is more than fast enough for the task at hand. I loaded the arXiv annotations to Redis, keyed on their arXiv ID, and updated my script to retrieve the arXiv annotation from Redis. That way I could have as many console windows as I wanted, each processing documents, using the same in-memory store of annotations.
graph LR
subgraph "Shared Redis"
NAS2[(NAS Drive)] --PDFs--> C1[Console 1] & C2[Console 2] & C3[Console 3] & C4[Console ...]
C1 & C2 & C3 & C4 <--> |Annotation lookup| R[(Shared Redis)]
end
It was beautiful. With the script running, my desktop looked like something out of a cheesy 90s hacker movie. The launcher would handle the spawning of console windows, and as soon as one finished and closed, another was opened. I tinkered with the spawn count until I reached a balance which optimized both the global processing rate and the NAS volume utilization.
Over the next two days, the script worked its way through the 4.6 million PDF mirror. Console windows would pop up, briefly interrupting my work; a reassuring reminder that another batch had finished.
By Friday afternoon the backfill was complete.
The Autopsy
Let's look again at 1706.03762v7.pdf from the GCS arXiv bucket:
dorsal file scan /mnt/b/arxiv_mirror/pdf/1706/1706.03762v7.pdf
📄 Scanning metadata for 1706.03762v7.pdf
╭────────────────────────── File Record: 1706.03762v7.pdf ───────────────────────────╮
│ │
│ Hashes │
│ SHA-256: b7d72988fd8107d07f7d278bf0ba6621adb6ed47df74be4014fa4a01f03aff6a │
│ │
│ File Info │
│ Full Path: /mnt/b/arxiv_mirror/pdf/1706/1706.03762v7.pdf │
│ Modified: 2023-08-03 01:07:33 │
│ Name: 1706.03762v7.pdf │
│ Size: 2 MiB │
│ Media Type: application/pdf │
│ │
│ Tags │
│ No tags found. │
│ │
│ Pdf Info → file/pdf │
│ creator: LaTeX with hyperref │
│ producer: pdfTeX-1.40.25 │
│ version: 1.5 │
│ page_count: 15 │
│ creation_date: 2023-08-03T00:07:29Z │
│ modified_date: 2023-08-03T00:07:29Z │
│ │
│ │
╰────────────────────────────────────────────────────────────────────────────────────╯
The creation_date field under the PDF Info annotation is 2023-08-03T00:07:29Z. If we compare this timestamp to the submission date recorded on arXiv for that version of the paper (2023-08-03T00:41:18Z) we can see that they closely line up. The document was compiled by arXiv's backend when it was submitted.
This is something we might expect, and it aligns with my earlier mental model of arXiv as a static cache for PDFs. Under this mental model:
- A paper is submitted to arXiv - typically as a LaTeX bundle.
- arXiv compiles it to a PDF (in this example using version
1.40.25of pdfTex). - Later, when someone visits the PDF download URL, they are served the compiled PDF.
With that in mind, let's look once more at another 1706.03762v7.pdf, this one downloaded from the arXiv website in February 2026:
dorsal file scan /mnt/c/Users/Rio/Downloads/1706.03762v7.pdf
📄 Scanning metadata for 1706.03762v7.pdf
╭────────────────────────── File Record: 1706.03762v7.pdf ───────────────────────────╮
│ │
│ Hashes │
│ SHA-256: bdfaa68d8984f0dc02beaca527b76f207d99b666d31d1da728ee0728182df697 │
│ │
│ File Info │
│ Full Path: /mnt/c/Users/Rio/Downloads/1706.03762v7.pdf │
│ Modified: 2026-02-07 13:43:07 │
│ Name: 1706.03762v7.pdf │
│ Size: 2 MiB │
│ Media Type: application/pdf │
│ │
│ Tags │
│ No tags found. │
│ │
│ Pdf Info → file/pdf │
│ creator: LaTeX with hyperref │
│ producer: pdfTeX-1.40.25 │
│ version: 1.5 │
│ page_count: 15 │
│ creation_date: 2024-04-10T21:11:43Z │
│ modified_date: 2024-04-10T21:11:43Z │
│ │
│ │
╰────────────────────────────────────────────────────────────────────────────────────╯
According to the creation_date field, this variant of the PDF was compiled from its LaTeX source a full 8 months after its submission date.
This demonstrates that arXiv does not fit neatly into the static cache model. Under a static cache model, after a document is submitted to arXiv, it is compiled once. Then that compiled document is served forever.
Instead we should probably see arXiv as a PDF generation system, as it is still able and willing to generate PDFs from source much later than submission.
But how much later?
The Bucket
To get a fuller picture, I tracked the creation_date field across the entire set of 4.6 million PDFs in the GCS bucket.1
Click here to view as a table
| Year | Total Submitted | Compiled Near Submission | % Compiled Near Submission |
|---|---|---|---|
| 1993 | 5,099 | 0 | 0.0% |
| 1994 | 7,593 | 0 | 0.0% |
| 1995 | 9,929 | 0 | 0.0% |
| 1996 | 15,761 | 0 | 0.0% |
| 1997 | 19,508 | 0 | 0.0% |
| 1998 | 23,858 | 1 | 0.0% |
| 1999 | 27,206 | 2 | 0.0% |
| 2000 | 29,904 | 10 | 0.0% |
| 2001 | 32,161 | 149 | 0.5% |
| 2002 | 35,201 | 436 | 1.2% |
| 2003 | 38,522 | 855 | 2.2% |
| 2004 | 42,805 | 1,362 | 3.2% |
| 2005 | 45,855 | 1,757 | 3.8% |
| 2006 | 49,326 | 2,216 | 4.5% |
| 2007 | 54,114 | 2,547 | 4.7% |
| 2008 | 56,144 | 11,737 | 20.9% |
| 2009 | 60,274 | 17,699 | 29.4% |
| 2010 | 64,768 | 25,986 | 40.1% |
| 2011 | 71,329 | 31,211 | 43.8% |
| 2012 | 79,395 | 42,823 | 53.9% |
| 2013 | 87,943 | 65,404 | 74.4% |
| 2014 | 93,249 | 90,591 | 97.1% |
| 2015 | 101,722 | 99,647 | 98.0% |
| 2016 | 110,207 | 108,099 | 98.1% |
| 2017 | 120,837 | 118,590 | 98.1% |
| 2018 | 138,243 | 135,150 | 97.8% |
| 2019 | 153,544 | 150,332 | 97.9% |
| 2020 | 174,997 | 171,500 | 98.0% |
| 2021 | 179,665 | 176,045 | 98.0% |
| 2022 | 183,957 | 180,818 | 98.3% |
| 2023 | 206,485 | 203,170 | 98.4% |
| 2024 | 241,833 | 237,576 | 98.2% |
| 2025 | 125,701 | 121,700 | 96.8% |
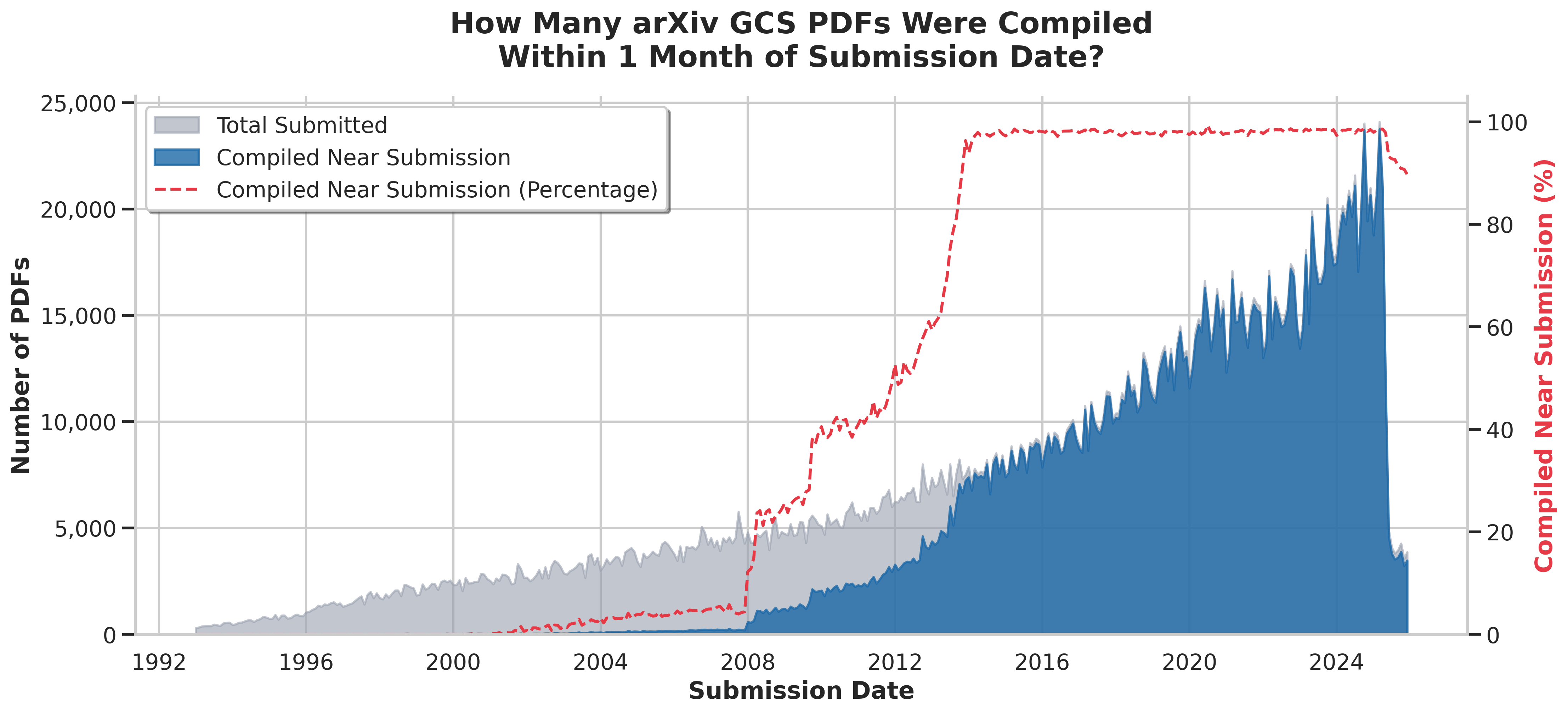
How to Read this Chart
The Gray Area: Shows the total arXiv submissions over time. This closely tracks the trend seen in arXiv.org's official monthly submission data.
The Blue Area: Shows the absolute count of how many documents have a
creation_datevalue which is within one month of submission.The Red Line: Shows the percentage difference between the Gray area and the Blue area.
Some observations:
-
Since 2014, the PDFs added to the bucket were almost all compiled around their submission date.
-
Upwards of 97% of documents have a
creation_datefield which is within one month of their submission -
This suggests that the documents are pushed to the GCS bucket soon after submission, and are not modified at a later date.
-
-
Prior to 2012, the majority of documents have a future
creation_datevalue-
The proportion of documents which were compiled close to their submission date drops dramatically prior to 2012.
-
Since the GCS bucket did not exist (or at least was not public) until 2020, this indicates regular or occasional re-compiling of documents was well established prior to the GCS bucket launching.
-
-
There is some evidence of systematic recompiling of documents
-
As we go further back in time, the red line does not show a gradual tapering off. Instead we see dramatic drops in the number of documents compiled near submission date.
-
The values change most swiftly around 2008 and 2014. This may be evidence of batch PDF recompilation events
-
To get a clearer idea of the trends in the creation_date field, I subtracted the total papers submitted each month from the number compiled:
Click here to view as a table
| Year | Papers Submitted | PDFs Created | Net PDFs Created | Cumulative Difference |
|---|---|---|---|---|
| 1991 | 259 | 0 | -259 | -259 |
| 1992 | 2540 | 0 | -2540 | -2799 |
| 1993 | 5099 | 0 | -5099 | -7898 |
| 1994 | 7593 | 0 | -7593 | -15491 |
| 1995 | 9929 | 0 | -9929 | -25420 |
| 1996 | 15761 | 6 | -15755 | -41175 |
| 1997 | 19508 | 10 | -19498 | -60673 |
| 1998 | 23858 | 14 | -23844 | -84517 |
| 1999 | 27206 | 23 | -27183 | -111700 |
| 2000 | 29904 | 54 | -29850 | -141550 |
| 2001 | 32161 | 225 | -31936 | -173486 |
| 2002 | 35201 | 631 | -34570 | -208056 |
| 2003 | 38522 | 1165 | -37357 | -245413 |
| 2004 | 42805 | 1988 | -40817 | -286230 |
| 2005 | 45855 | 2591 | -43264 | -329494 |
| 2006 | 49326 | 3041 | -46285 | -375779 |
| 2007 | 54114 | 3419 | -50695 | -426474 |
| 2008 | 56144 | 136911 | 80767 | -345707 |
| 2009 | 60274 | 19493 | -40781 | -386488 |
| 2010 | 64768 | 27747 | -37021 | -423509 |
| 2011 | 71329 | 41806 | -29523 | -453032 |
| 2012 | 79395 | 44800 | -34595 | -487627 |
| 2013 | 87943 | 241387 | 153444 | -334183 |
| 2014 | 93249 | 418734 | 325485 | -8698 |
| 2015 | 101722 | 110201 | 8479 | -219 |
| 2016 | 110207 | 111369 | 1162 | 943 |
| 2017 | 120837 | 121572 | 735 | 1678 |
| 2018 | 138243 | 137874 | -369 | 1309 |
| 2019 | 153544 | 153642 | 98 | 1407 |
| 2020 | 174997 | 174600 | -397 | 1010 |
| 2021 | 179665 | 179933 | 268 | 1278 |
| 2022 | 183957 | 183791 | -166 | 1112 |
| 2023 | 206485 | 206692 | 207 | 1319 |
| 2024 | 241833 | 241843 | 10 | 1329 |
| 2025 | 125701 | 124458 | -1243 | 86 |
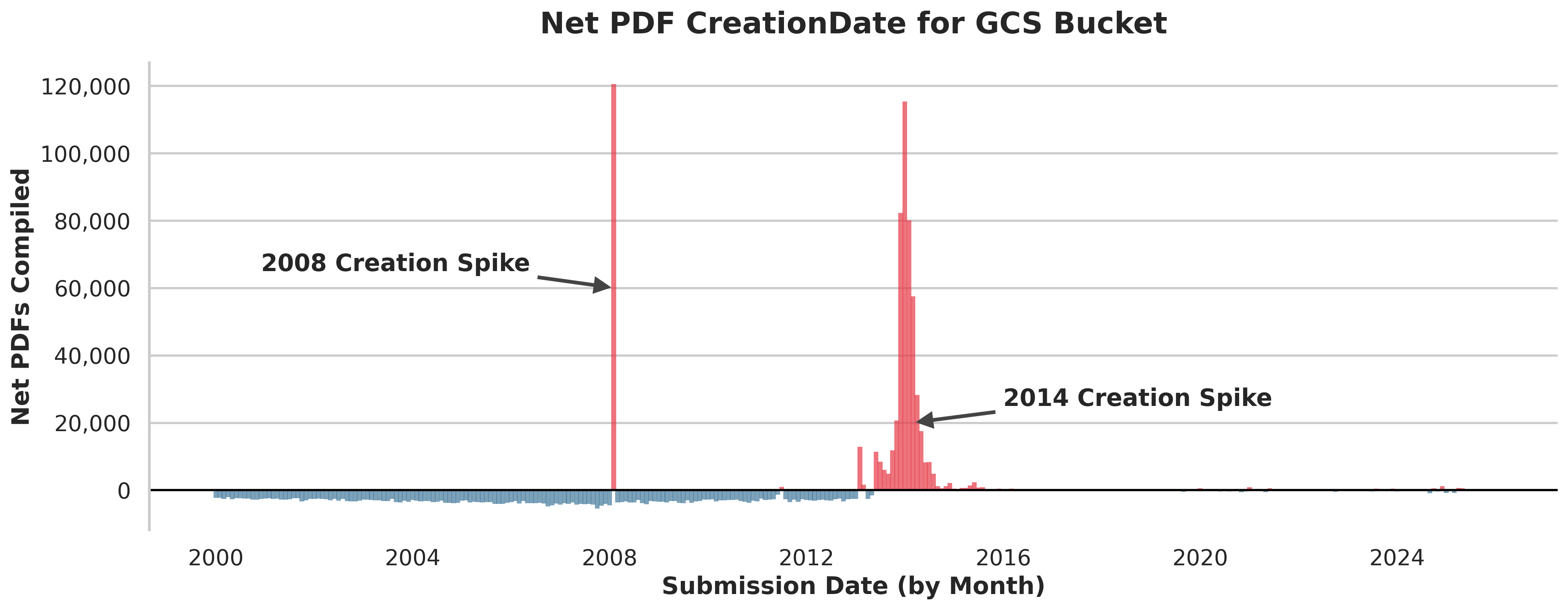
How to Read this Chart
Each bar represents the net PDFs created for one month (e.g. February 2014).
Blue bars are negative values, meaning the bucket contains fewer documents whose
creation_datematches that month than the month's total submissions.Red bars are positive values, meaning the bucket contains more documents whose
creation_datematches that month than the month's total submissions.
Observations:
-
There is strong evidence of batch PDF compilation "events"
-
Massive positive (red) spikes in 2008 and 2014 show hundreds of thousands of documents being compiled in a relatively short space of time.
-
While we can't be sure why these documents were rebuilt, it is evidence of systematic, bulk recompilation of PDFs.
-
-
The original PDFs for older papers no longer exist in the bucket.
- The vast majority of older documents in the bucket were created long after their submission date.
-
For papers submitted after 2014, the GCS bucket retains the 'first pressing'.
-
From 2015, the net activity flatlines to near zero. The compilation dates reflect the submission dates.
-
This tells us that once a PDF lands in the bucket, it is not updated. Even if the arXiv frontend regenerates documents from its source, the GCS bucket acts as a time capsule, preserving the "first pressing" of each document.
-
I could have spent longer profiling the documents in the GCS bucket, but fundamentally, the big question I wanted to answer was this: could I build an annotation retrieval model using the data from the GCS bucket?
To answer this, I needed to actually compare the GCS bucket data with papers downloaded fresh from arXiv.
The Sample
I took a stratified sample of PDFs from the arXiv backfill - 50 per year - and I re-downloaded all of them from the web. I was careful to preserve the full ID for each, and I then used a script to compare the hashes of each to the hashes of the equivalent (same paper, same version) document from the GCS bucket. 1991 to 2026. 36 years. 1800 documents in total.2
Click here to view as a table
| Submission Year | Total Sampled | Exact Matches | Match Rate |
|---|---|---|---|
| 1991 | 50 | 0 | 0.0% |
| 1992 | 50 | 0 | 0.0% |
| 1993 | 50 | 0 | 0.0% |
| 1994 | 50 | 0 | 0.0% |
| 1995 | 50 | 0 | 0.0% |
| 1996 | 50 | 0 | 0.0% |
| 1997 | 50 | 0 | 0.0% |
| 1998 | 50 | 1 | 2.0% |
| 1999 | 50 | 0 | 0.0% |
| 2000 | 50 | 1 | 2.0% |
| 2001 | 50 | 0 | 0.0% |
| 2002 | 49 | 2 | 4.1% |
| 2003 | 50 | 3 | 6.0% |
| 2004 | 50 | 1 | 2.0% |
| 2005 | 50 | 5 | 10.0% |
| 2006 | 48 | 2 | 4.2% |
| 2007 | 50 | 3 | 6.0% |
| 2008 | 50 | 3 | 6.0% |
| 2009 | 50 | 5 | 10.0% |
| 2010 | 50 | 5 | 10.0% |
| 2011 | 49 | 3 | 6.1% |
| 2012 | 50 | 9 | 18.0% |
| 2013 | 50 | 9 | 18.0% |
| 2014 | 50 | 9 | 18.0% |
| 2015 | 50 | 5 | 10.0% |
| 2016 | 50 | 9 | 18.0% |
| 2017 | 50 | 15 | 30.0% |
| 2018 | 50 | 21 | 42.0% |
| 2019 | 50 | 29 | 58.0% |
| 2020 | 50 | 30 | 60.0% |
| 2021 | 50 | 30 | 60.0% |
| 2022 | 50 | 49 | 98.0% |
| 2023 | 50 | 48 | 96.0% |
| 2024 | 50 | 50 | 100.0% |
| 2025 | 50 | 44 | 88.0% |
| 2026 | 50 | 49 | 98.0% |
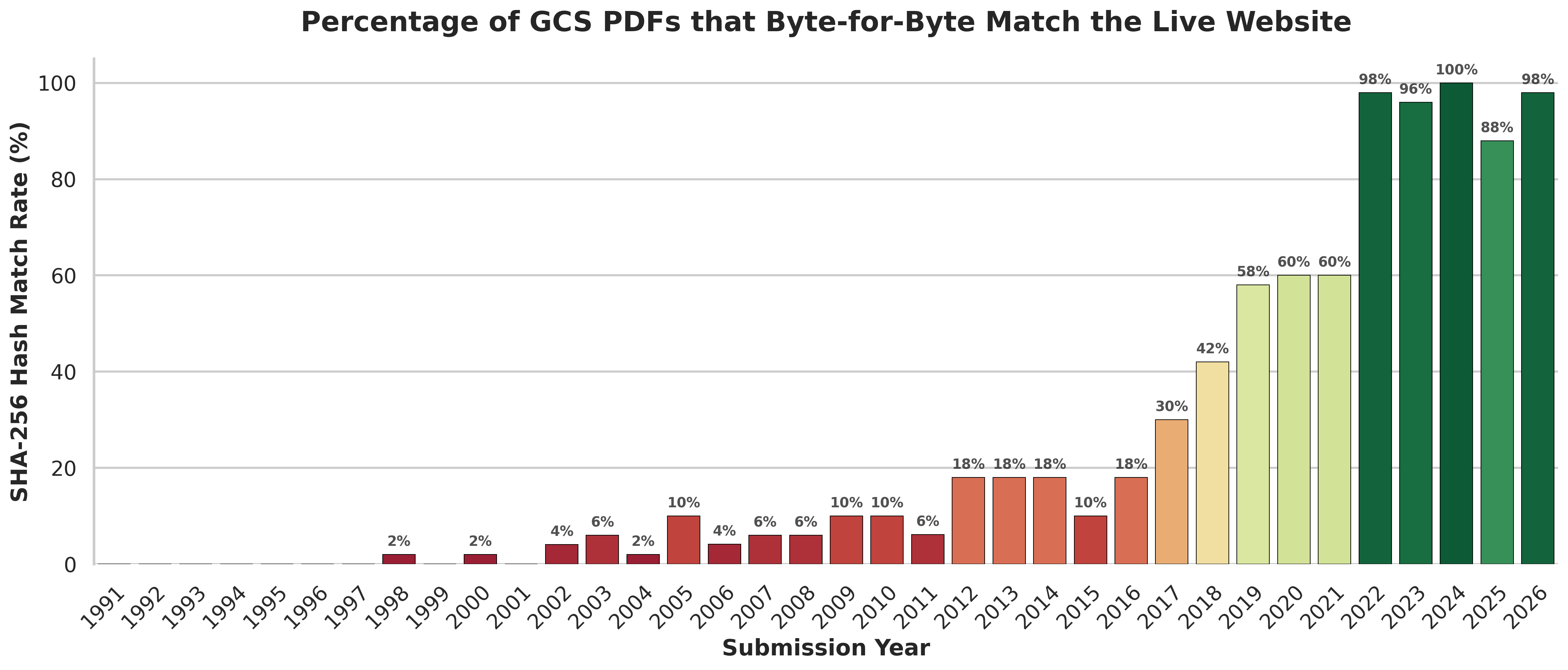
How to Read this Chart
- Each bar represents one year and shows the percentage of PDFs that were exact byte-for-byte matches with their GCS bucket counterparts (i.e. same paper, same version).
All of my doubts were confirmed. The distribution in this bar chart closely mirrors what we saw earlier, only in much more stark terms. This was undeniable evidence of documents being systematically re-built over time. The further back in time the less likely the live PDF was to be identical to that in the GCS bucket.
It seemed clear to me that the GCS papers were not the ideal fit for my defined task.
Armed with this knowledge, there was only one thing left to do: build the plugin.
The Plugin
Plugins (AKA Dorsal Annotation Models) extend Dorsal's ability to do metadata extraction tasks. Think of them as functions whose input is a file path, and whose output is a validation JSON.
The goal of this plugin: output an arXiv annotation which summarizes a PDF.
Despite the bumps along the way, I figured it was worth seeing this through to the end.
So I continued. Maybe it would make a good write-up. A cautionary tale.
The first version of the model was pretty straightforward:
- Hash the file bytes to produce a SHA-256 hash, e.g.
e481db0333b3e7011406ecd6932d54bcc2829f0da4ffbc87e5552bf07d812985 - Query DorsalHub API for that exact hash
- If a record is found, parse out the
dorsal/arxivannotation and return it
I sampled a fresh batch of documents from arXiv to verify the model.
Its performance was pretty much what I expected:
Click here to view as a table
| Submission Year | Sample Size | Success | Fail | Recall (%) |
|---|---|---|---|---|
| 1991 | 50 | 0 | 50 | 0% |
| 1992 | 50 | 0 | 50 | 0% |
| 1993 | 50 | 0 | 50 | 0% |
| 1994 | 50 | 0 | 50 | 0% |
| 1995 | 50 | 0 | 50 | 0% |
| 1996 | 50 | 0 | 50 | 0% |
| 1997 | 50 | 0 | 50 | 0% |
| 1998 | 50 | 0 | 50 | 0% |
| 1999 | 50 | 0 | 50 | 0% |
| 2000 | 50 | 1 | 49 | 2% |
| 2001 | 50 | 0 | 50 | 0% |
| 2002 | 50 | 1 | 49 | 2% |
| 2003 | 50 | 2 | 48 | 4% |
| 2004 | 50 | 5 | 45 | 10% |
| 2005 | 50 | 2 | 48 | 4% |
| 2006 | 50 | 3 | 47 | 6% |
| 2007 | 50 | 2 | 48 | 4% |
| 2008 | 50 | 2 | 48 | 4% |
| 2009 | 50 | 2 | 48 | 4% |
| 2010 | 50 | 5 | 45 | 10% |
| 2011 | 50 | 4 | 46 | 8% |
| 2012 | 50 | 8 | 42 | 16% |
| 2013 | 50 | 9 | 41 | 18% |
| 2014 | 50 | 8 | 42 | 16% |
| 2015 | 50 | 8 | 42 | 16% |
| 2016 | 50 | 8 | 42 | 16% |
| 2017 | 50 | 13 | 37 | 26% |
| 2018 | 50 | 26 | 24 | 52% |
| 2019 | 50 | 27 | 23 | 54% |
| 2020 | 50 | 34 | 16 | 68% |
| 2021 | 50 | 38 | 12 | 76% |
| 2022 | 50 | 46 | 4 | 92% |
| 2023 | 50 | 50 | 0 | 100% |
| 2024 | 50 | 49 | 1 | 98% |
| 2025 | 50 | 46 | 4 | 92% |
| 2026 | 50 | 50 | 0 | 100% |
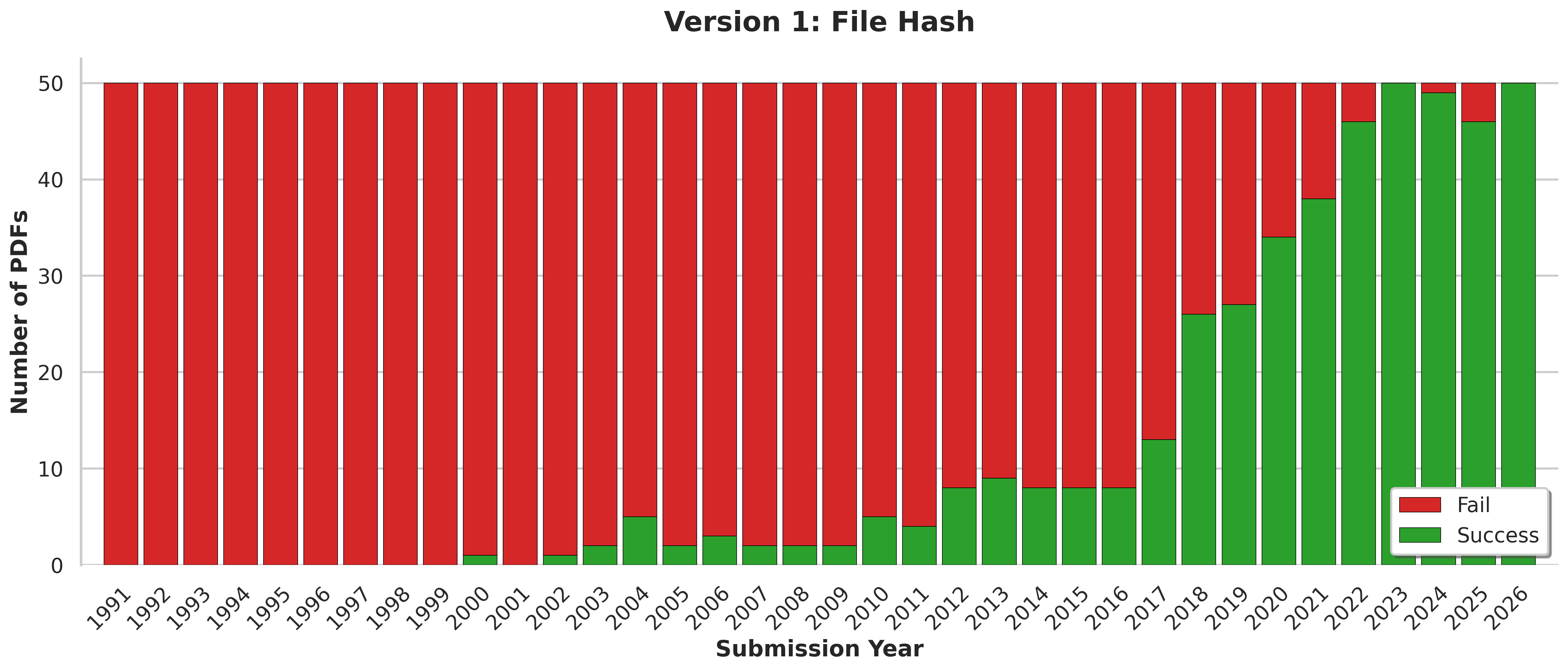
How to Read this Chart
Each stacked bar represents a sample of 50 PDFs submitted within a single year.
The green portion represents files where the model could fetch the metadata
The red portion represents files where the model failed to fetch the metadata
Some findings:
- The model's average Recall was 24.9%, meaning it could return the annotation for just 1 in 4 documents sampled.
- The recall tapers off to 0% as we go back in time, mirroring earlier findings
- Conversely, recent documents have the highest recall, suggesting arXiv has not recompiled most of those PDFs from their "first pressing" yet.
While analysing the failures, I spotted a pattern in many of the documents. Here's an example:
dorsal file scan /mnt/c/arxiv_batch/9206023v1.pdf
📄 Scanning metadata for 9206023v1.pdf
╭───────────────────── File Record: 9206023v1.pdf (from cache) ──────────────────────╮
│ │
│ Hashes │
│ SHA-256: e481db0333b3e7011406ecd6932d54bcc2829f0da4ffbc87e5552bf07d812985 │
│ BLAKE3: efe99342b87a09d58e52ad97b99bf25ced1bb94256d3b4d99fb700f424bca20e │
│ │
│ File Info │
│ Full Path: /mnt/c/arxiv_batch/9206023v1.pdf │
│ Modified: 2026-03-01 09:19:24 │
│ Name: 9206023v1.pdf │
│ Size: 271 KiB │
│ Media Type: application/pdf │
│ │
│ Tags │
│ No tags found. │
│ │
│ Pdf Info → file/pdf │
│ title: arXiv:hep-th/9206023v1 4 Jun 1992 │
│ creator: dvips(k) 5.86 Copyright 1999 Radical Eye Software │
│ producer: GPL Ghostscript GIT PRERELEASE 9.22 │
│ version: 1.4 │
│ page_count: 33 │
│ creation_date: 2018-10-25T21:30:06-04:00 │
│ modified_date: 2018-10-25T21:30:06-04:00 │
│ │
│ │
╰────────────────────────────────────────────────────────────────────────────────────╯
Under the Pdf Info annotation, we can clearly see the title field is already populated with the arXiv ID hep-th/9206023v1.
This document is telling us what it is. Right there, in a standard core PDF metadata field:
strings /mnt/c/arxiv_batch/9206023v1.pdf | grep /Title
/Title(arXiv:hep-th/9206023v1 4 Jun 1992)>>endobj
This provided an easy win for boosting the recall. For each document I could look it up in two ways: first by the content hash and then, if that failed, by its arXiv ID.
The embedded ID wasn't available in all of the failures I inspected, but it was in enough of them to make it worth pursuing.
So I decided to re-index the annotations to DorsalHub. This time, each annotation would be linked to a different hash: a hash which represents the arXiv ID. All I had to do was create a tiny text file for each arXiv ID, containing that ID as a string.
Example: hep-th_9206023.txt whose content is the string hep-th/9206023.
graph LR
B(File Record)
C[hep-th_9206023.txt] --> B
A[dorsal/arxiv Annotation] ---> B
B -- "Publish" --> D[(DorsalHub API)]
Generating hashes for millions of short strings is a blissfully fast task. I linked each arXiv annotation and published to the DorsalHub API. The entire backfill was complete within a couple of hours.
I now had a secondary queryable dataset, to power a lookup process based entirely on the arXiv ID:
flowchart LR
A@{ shape: doc, label: "9206023.pdf" }
subgraph PluginBox[Plugin: ArXivPDF]
B(Hash and Lookup)
end
A -- "arXiv ID: hep-th/9206023" --> B
B -- "076c051fae7b61c757a..." --> C[(DorsalHub API)]
C -- "Annotation: dorsal/arxiv" --> PluginBox
I then built a Version 2 of the ArXivPDF model, which made use of this new data.
Version 2 of the model adds 3 extra steps over Version 1:
- Hash the file bytes to produce a SHA-256 hash,
- Query DorsalHub API for that exact hash
- If a record is found, parse out the
dorsal/arxivannotation, return it and exit - Attempt to retrieve the arXiv ID from the PDF metadata
titlefield - If the arXiv ID is found, convert it to a SHA-256 hash, and query the DorsalHub API
- If a record is found, parse out the
dorsal/arxivannotation, return it and exit.
This turned out to be worth the extra effort. It boosted the recall of the model significantly:
Click here to view as a table
| Submission Year | Sample Size | Success | Fail | Recall (%) |
|---|---|---|---|---|
| 1991 | 50 | 49 | 1 | 98% |
| 1992 | 50 | 49 | 1 | 98% |
| 1993 | 50 | 39 | 11 | 78% |
| 1994 | 50 | 26 | 24 | 52% |
| 1995 | 50 | 30 | 20 | 60% |
| 1996 | 50 | 35 | 15 | 70% |
| 1997 | 50 | 44 | 6 | 88% |
| 1998 | 50 | 46 | 4 | 92% |
| 1999 | 50 | 47 | 3 | 94% |
| 2000 | 50 | 45 | 5 | 90% |
| 2001 | 50 | 43 | 7 | 86% |
| 2002 | 50 | 44 | 6 | 88% |
| 2003 | 50 | 21 | 29 | 42% |
| 2004 | 50 | 19 | 31 | 38% |
| 2005 | 50 | 12 | 38 | 24% |
| 2006 | 50 | 16 | 34 | 32% |
| 2007 | 50 | 7 | 43 | 14% |
| 2008 | 50 | 7 | 43 | 14% |
| 2009 | 50 | 4 | 46 | 8% |
| 2010 | 50 | 8 | 42 | 16% |
| 2011 | 50 | 10 | 40 | 20% |
| 2012 | 50 | 8 | 42 | 16% |
| 2013 | 50 | 11 | 39 | 22% |
| 2014 | 50 | 12 | 38 | 24% |
| 2015 | 50 | 10 | 40 | 20% |
| 2016 | 50 | 10 | 40 | 20% |
| 2017 | 50 | 13 | 37 | 26% |
| 2018 | 50 | 26 | 24 | 52% |
| 2019 | 50 | 27 | 23 | 54% |
| 2020 | 50 | 34 | 16 | 68% |
| 2021 | 50 | 38 | 12 | 76% |
| 2022 | 50 | 46 | 4 | 92% |
| 2023 | 50 | 50 | 0 | 100% |
| 2024 | 50 | 49 | 1 | 98% |
| 2025 | 50 | 46 | 4 | 92% |
| 2026 | 50 | 50 | 0 | 100% |
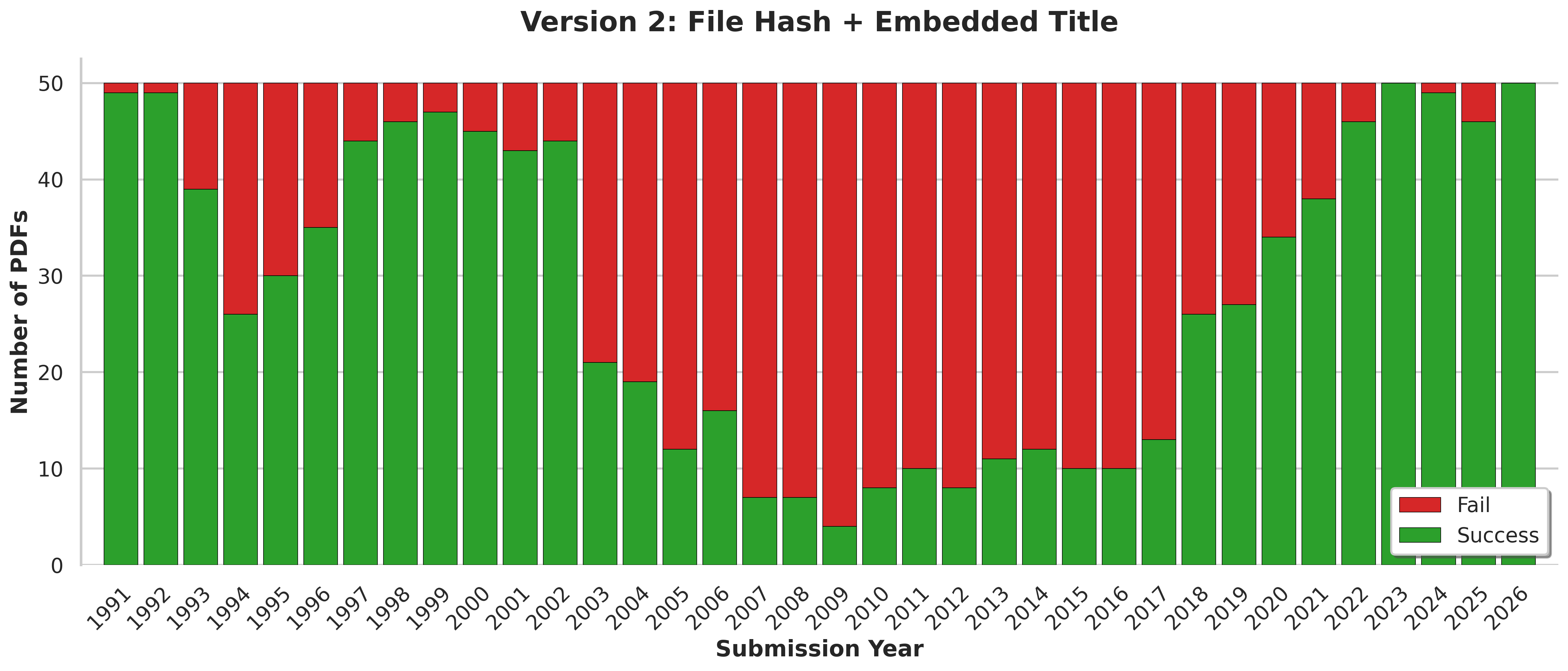
Some findings:
- The model's average Recall was now 57.3%, meaning it could return the annotation for the majority of documents sampled.
- The recall tapers off to 0% as we go back in time. It seems likely that a feature of the batch recompiling of those 90s documents with Ghostscript included manually embedding a title in a standard format e.g.
arXiv:hep-th/9206023v1 4 Jun 1992. - The recall was lowest among documents published in the 2000s and early 2010s, most of which had not been stamped with a standard title containing a crisp arXiv ID
Now that I had queryable data where I could provide an arXiv ID and get back an arXiv annotation, one further improvement for the model was staring me in the face: the file name.
When you download a paper from arXiv, most of the time its ID is included in the file name. This is always the case for papers submitted after 2007.
For pre-2007 papers, only a partial identifier is included in the filename. For example, the papers gr-qc/9407013 and chao-dyn/9407013 both download with the exact same default filename: 9407013v1.pdf. This means there's no clean way to map back from the file name to a pre-2007 arXiv ID. For that reason, I had to exclude pre-2007 papers from my filename check logic when building Version 3.
Here's how Version 3 tackles the problem (Steps 7 to 9 are new):
- Hash the file bytes to produce a SHA-256 hash,
- Query DorsalHub API for that exact hash
- If a record is found, parse out the
dorsal/arxivannotation, return it and exit - Attempt to retrieve the arXiv ID from the PDF metadata
titlefield - If the arXiv ID is found, convert it to a SHA-256 hash, and query the DorsalHub API
- If a record is found, parse out the
dorsal/arxivannotation, return it and exit. - If the arXiv ID was not found, parse it from the filename (post-2007 format only)
- Convert the arXiv ID to a SHA-256 hash, and query the DorsalHub API
- If a record is found, parse out the
dorsal/arxivannotation, return it and exit.
Click here to view as a table
| Submission Year | Sample Size | Success | Fail | Recall (%) |
|---|---|---|---|---|
| 1991 | 50 | 49 | 1 | 98% |
| 1992 | 50 | 49 | 1 | 98% |
| 1993 | 50 | 39 | 11 | 78% |
| 1994 | 50 | 26 | 24 | 52% |
| 1995 | 50 | 30 | 20 | 60% |
| 1996 | 50 | 35 | 15 | 70% |
| 1997 | 50 | 44 | 6 | 88% |
| 1998 | 50 | 46 | 4 | 92% |
| 1999 | 50 | 47 | 3 | 94% |
| 2000 | 50 | 45 | 5 | 90% |
| 2001 | 50 | 43 | 7 | 86% |
| 2002 | 50 | 44 | 6 | 88% |
| 2003 | 50 | 21 | 29 | 42% |
| 2004 | 50 | 19 | 31 | 38% |
| 2005 | 50 | 12 | 38 | 24% |
| 2006 | 50 | 16 | 34 | 32% |
| 2007 | 50 | 37 | 13 | 74% |
| 2008 | 50 | 50 | 0 | 100% |
| 2009 | 50 | 50 | 0 | 100% |
| 2010 | 50 | 50 | 0 | 100% |
| 2011 | 50 | 50 | 0 | 100% |
| 2012 | 50 | 50 | 0 | 100% |
| 2013 | 50 | 50 | 0 | 100% |
| 2014 | 50 | 50 | 0 | 100% |
| 2015 | 50 | 50 | 0 | 100% |
| 2016 | 50 | 50 | 0 | 100% |
| 2017 | 50 | 50 | 0 | 100% |
| 2018 | 50 | 50 | 0 | 100% |
| 2019 | 50 | 50 | 0 | 100% |
| 2020 | 50 | 50 | 0 | 100% |
| 2021 | 50 | 50 | 0 | 100% |
| 2022 | 50 | 50 | 0 | 100% |
| 2023 | 50 | 50 | 0 | 100% |
| 2024 | 50 | 50 | 0 | 100% |
| 2025 | 50 | 50 | 0 | 100% |
| 2026 | 50 | 50 | 0 | 100% |
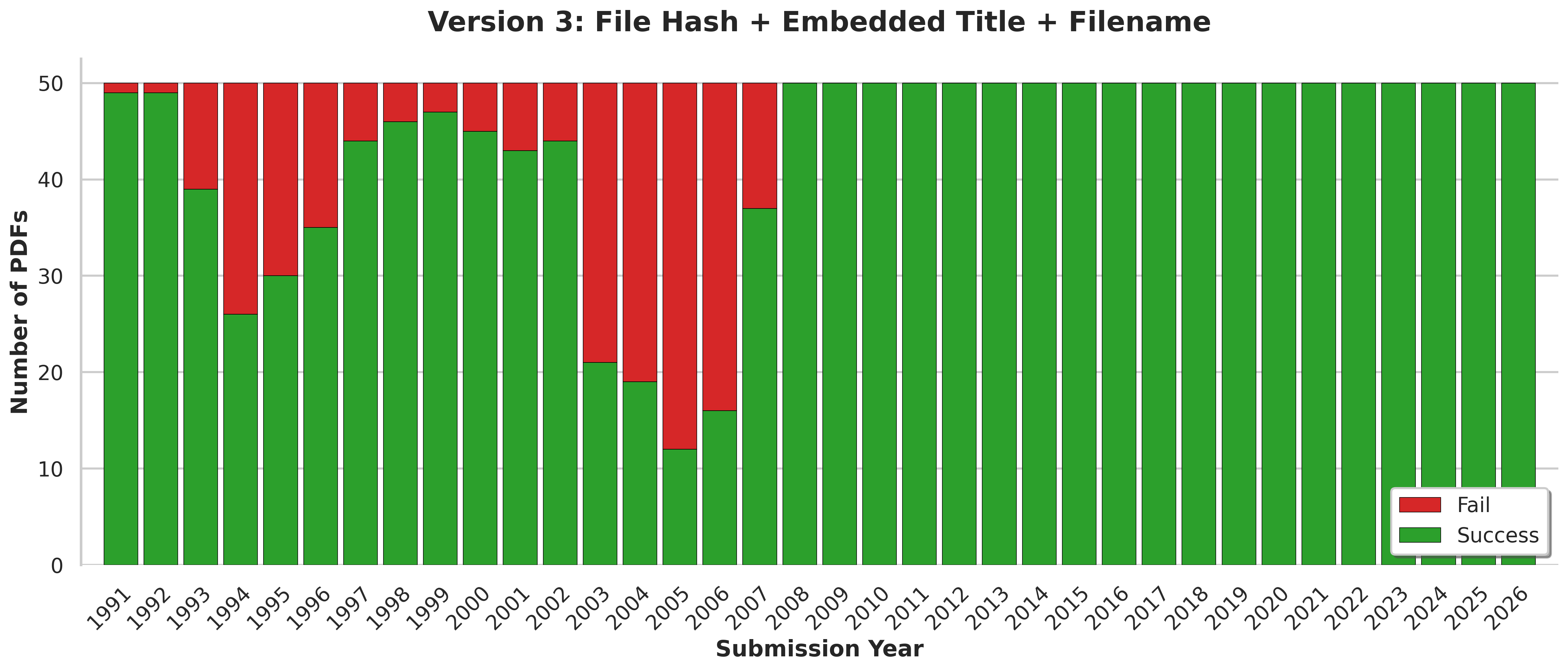
Some findings:
-
This model's average Recall is 86.2%. We have perfect recall after 2007, meaning all files sampled which could leverage the new filename-based approach were successful.
-
This is a testament to how complete the original arXiv Dataset is.
By this point, my weekend project had gone on for close to three weeks. While I could probably tinker around the edges and improve it here or there, the model does what I set out to do: it demonstrates annotation retrieval.
You can find the final model here: https://dorsalhub.com/models/dorsalhub/arxiv-pdf
Feel free to try it out! To date I've only backfilled arXiv annotations up to the end of January (hashes) and February (IDs), but you should expect reasonable performance for records before that.
And if you work (or play) with file metadata, in any capacity, please try out Dorsal.
-
For these visuals, the data was filtered to only include v1 of each document, though there's no indication that other versions exhibit different behavior. The submission figures also omit documents which where the Creation Date of the PDF is not reported by the PDF compilation tool, including a significant number of documents compiled with GenPDF in 2025. ↩
-
The working sample was 1796. From the sample I generated, four of the 1800 PDFs failed to download. One had been withdrawn; for the remaining three arXiv reported
Our automated source to PDF conversion system has failed to produce PDF for the paper(example). This was interesting in-and-of itself so I chose not to resample. ↩